Forking Around: Dangerous AI
How I Use LLMs to Make Infrastructure Work Suck Less
By James Brink, Tinkerer of Terror
Welcome to another installment of "Forking Around" - where I document my chaotic workflows as I stumble through the brave new world of AI. I'm shocked I actually wrote a second post, defying all expectations.
Beyond Vibe Coding: AI for the Infrastructure Crowd
I've been seeing a flood of blogs and videos lately about AI coding, specifically this new "vibe coding" trend. But I'm not seeing much about infrastructure, sysadmin, or operations use cases being shared. So I figured I'd show just one of many ways I dangerously use AI to make my work much faster.
The Great Ubuntu → NixOS Migration Adventure
I recently migrated a production server from Ubuntu to NixOS. I had done the original server setup well over a year ago, and since I'm an infra-as-code fanatic, I naturally used Ansible. Over time I slowly learned about NixOS and became more comfortable with it in production. When we needed to take the server offline to do some storage-related work, I decided this was a prime opportunity to ditch my miles of messy Ansible and sneak in NixOS.
I branched, tested locally for a few days with a VM verifying everything was in order, and after running final backups on the prod box, I used my shiny new NixOS configuration and nixos-anywhere to install NixOS remotely over SSH, completely replacing Ubuntu. This worked flawlessly.
So I killed a few birds with one stone and was very happy... things were working great, then one day our app randomly became unavailable. Simple Docker app behind an Nginx proxy... I quickly restarted it and all was well, but I introduced a new problem, and this really is not shocking with such a big migration. At the time of the incident, I did not have time to dig into why it happened, but I did have a gut feeling about the issue. For more context, the container was still live, no errors, the Nginx proxy was running but reporting timeouts... same old story.
Debugging with ADHD Brain: The Old Way vs. The AI Way
When I finally had time a few days later to dig into the issue, I had to mentally prepare myself for digging through all the logs, trying to keep the time offsets correct in my ADHD brain (I will never be able to do simple math in my head 😂).
I said fuck this... you know what... opened up my NixOS repo for this server in Windsurf, from here I just did the following:
Yo, read our project structure, specifically around Podman, and Nginx services and the specific Podman service/container that failed.
Then I scrolled back through the Slack channel to find the incident... copy-pasta'd that into the prompt, with a note specifying my time zone vs. the server's so it's aware of the offsets.
I told the agent DO NOT CHANGE ANYTHING, and told it to ssh user@server -c
The Forensic Magic
It found the log entries, and when I followed up with the fact the server was recently migrated and gave it the original docker-compose, it was able to confirm with confidence that the issue was truly just cgroup related. I did not explicitly set up Podman with enough resources, and this was further confirmed by the non-error messages about Puma's current memory usage.
Here's a snippet of the timeline that the AI put together (because it's a cold-blooded machine that doesn't feel my ADHD pain):
- 16:54:56 EDT: First "upstream timed out" error in nginx logs
- 16:56:03 EDT: Second "upstream timed out" error (
records API) - 16:57:26 EDT: Third "upstream timed out" error
- 17:37:00 EDT: Issues first reported in chat
- 17:41:21 - 17:42:56 EDT: PumaWorkerKiller consistently reporting high memory usage (656.6MB)
- 17:48:24 EDT: Systemd automatically restarted the service
- 17:49:39 EDT: Service fully restored
Look at that clean timeline! Do you have any idea how long it would have taken my scattered brain to piece that together manually? And it did the boring work of correlating the exact failure patterns across multiple log sources.
Now none of the above is terribly groundbreaking—any sysadmin could hunt these kinds of issues down. The real difference is the absolute speed at which I was able to find the root cause. This only took a few minutes at most.
Once I was satisfied and in agreement with the agent, I asked it to create a postmortem report for me and include the timeline of events. What it came back with was incredibly comprehensive, including a detailed root cause analysis that identified these issues:
Root Cause Analysis
The root cause of the service disruption was a combination of factors related to the recent migration from Ubuntu/Docker to NixOS/Podman:
-
Resource Management Differences:
- The Rails application was developed and tested in a Docker environment without explicit resource limits
- When migrated to Podman on NixOS, the application encountered different resource management behavior due to cgroup v2
- PumaWorkerKiller logs showed consistent high memory usage (657MB) before the failure
-
Container Runtime Differences:
- The migration from Docker to Podman introduced subtle differences in how containers are managed
- The cgroup configuration in NixOS wasn't properly set up to accommodate the container's resource needs
It even compared the original Docker config to my new NixOS setup:
Configuration Comparison
Docker Configuration:
web:
image: <REDACTED>
restart: always
network_mode: host
environment:
- VIRTUAL_PROTO=http
- VIRTUAL_PORT=20420
- VIRTUAL_HOST=<REDACTED>NixOS/Podman Configuration:
web = {
image = "<REDACTED>";
autoStart = true;
extraOptions = [ "--network=host" ];
environment = {
"RACK_ENV" = "production";
"RAILS_ENV" = "production";
"RAILS_MAX_THREADS" = "10";
"WEB_CONCURRENCY" = "1";
};
};I was impressed beyond impressed. I just easily saved myself hours of work... just making a timeline of events would make me want to mentally jump off a bridge.
The Bigger Point
What I'm trying to say, if I'm saying anything at all, is that these agents are great at so many things beyond just coding. Having the repo with the NixOS configuration just amplified the success and understanding of the problem.
Even better, the AI provided concrete fixes with example code:
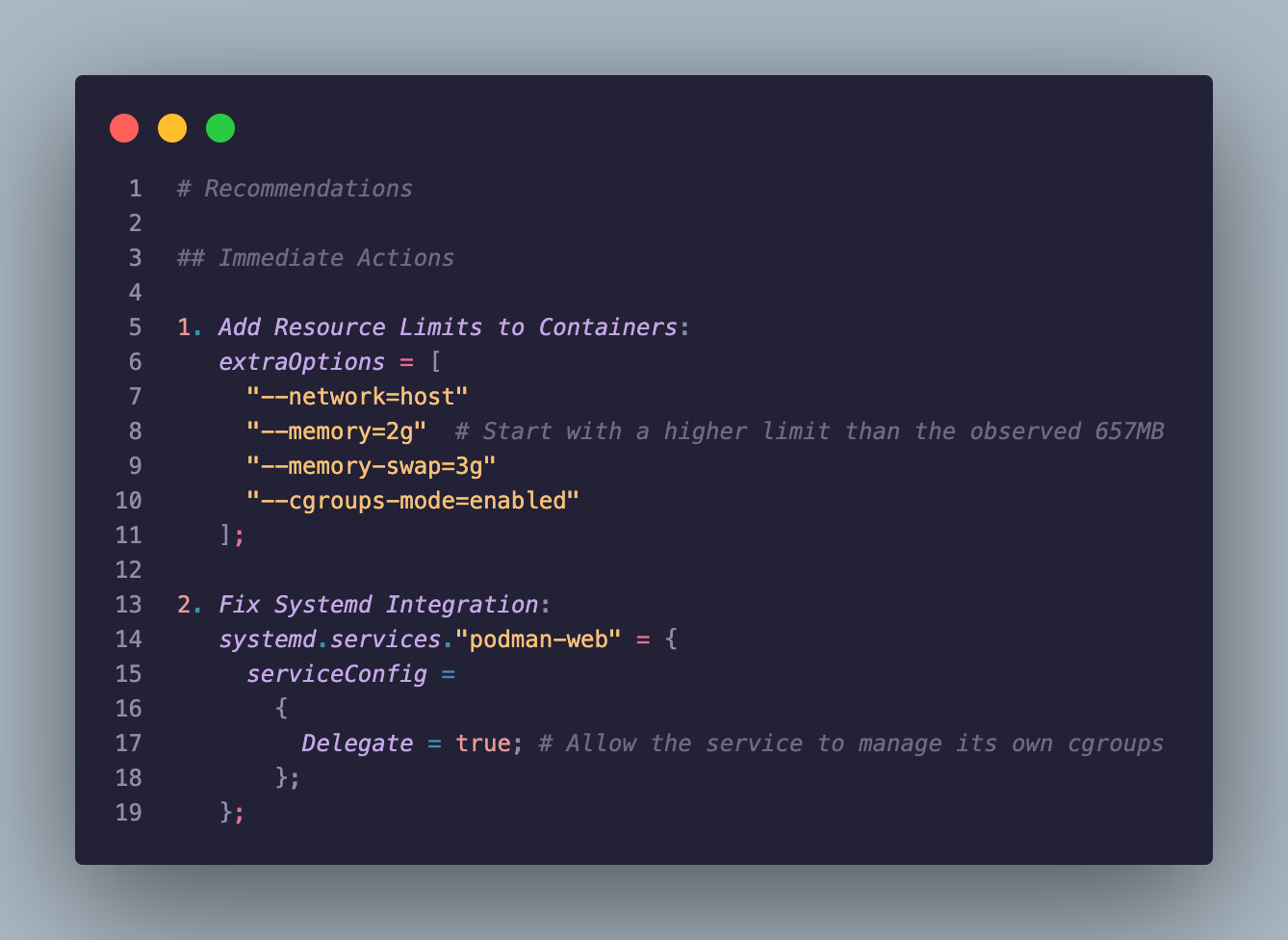
Like anything else, this takes common sense... just because I let the agent run everything as root does not mean you should 😂... you can apply the same techniques when working with things like AWS.
We all know how insanely long AWS CLI commands can be... this is another area where using an LLM just makes more sense because it can run through my entire AWS account faster than I can properly craft my first CLI command to do something trivial like listing CloudWatch shit 😂.
Tools I've Been Enjoying
When doing this kind of stuff, I've found Windsurf is pretty solid, but I have also enjoyed Goose. This fucker can be both insanely useful and dangerous... you have been warned lol.
The real power of these tools isn't just in the code they generate, but in how they can help us make sense of complex systems. For someone with my flavor of ADHD, having an AI that can quickly parse through logs, configs, and error messages is like finally having the missing manual for my brain.
If you're experimenting with AI for infrastructure work, start with something low-risk. Don't be like me and immediately give an AI agent root access to production systems. And when you inevitably ignore this advice, remember: good backups are your friend.